Statistical Learning
BACK: Statistical Learning
UNDER HEAVY CONSTRUCTION: NOT EVERYTHING MAY BE CORRECT.
Recall: We assumed that the our model is linear, thus our model takes the form:
\[Y=\beta_0+\beta_1*X\]I want to find some line that will model out what future values of \(Y\) would be given any input \(X\). i.e.: If I spent $300 on TV advertising, how much would I receive in sales? I will create this line by using the dataset and trying to find a line that minimizes the distance between all of the points and the points the line creates.
I have my model. It has those parameters \(B_0\) and \(B_1\), but we know that we’re probably not going to have the perfect, exact model, so we assume that there’s going to be some error where the estimated point is off from the dataset point. To calculate the distance, which we also call the residual, we would use:
\[Residual=y_i-\hat{y}_i\]But there are some points that are above or below the model, so we handle that by squaring the values.
\[Residual Squared = (y_i-\hat{y}_i)^2\]And we also want to consider ALL the dataset points and the estimated points, so we sum it over the entire dataset. This is equivalent to the residual squared, noted as:
\[RSS=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2=\sum_{i=1}^{n}(\varepsilon_i)^2\]We call this the residual sum of squares (\(RSS\)). Using this equation, we can actually solve for parameters \(B_0\) and \(B_1\).
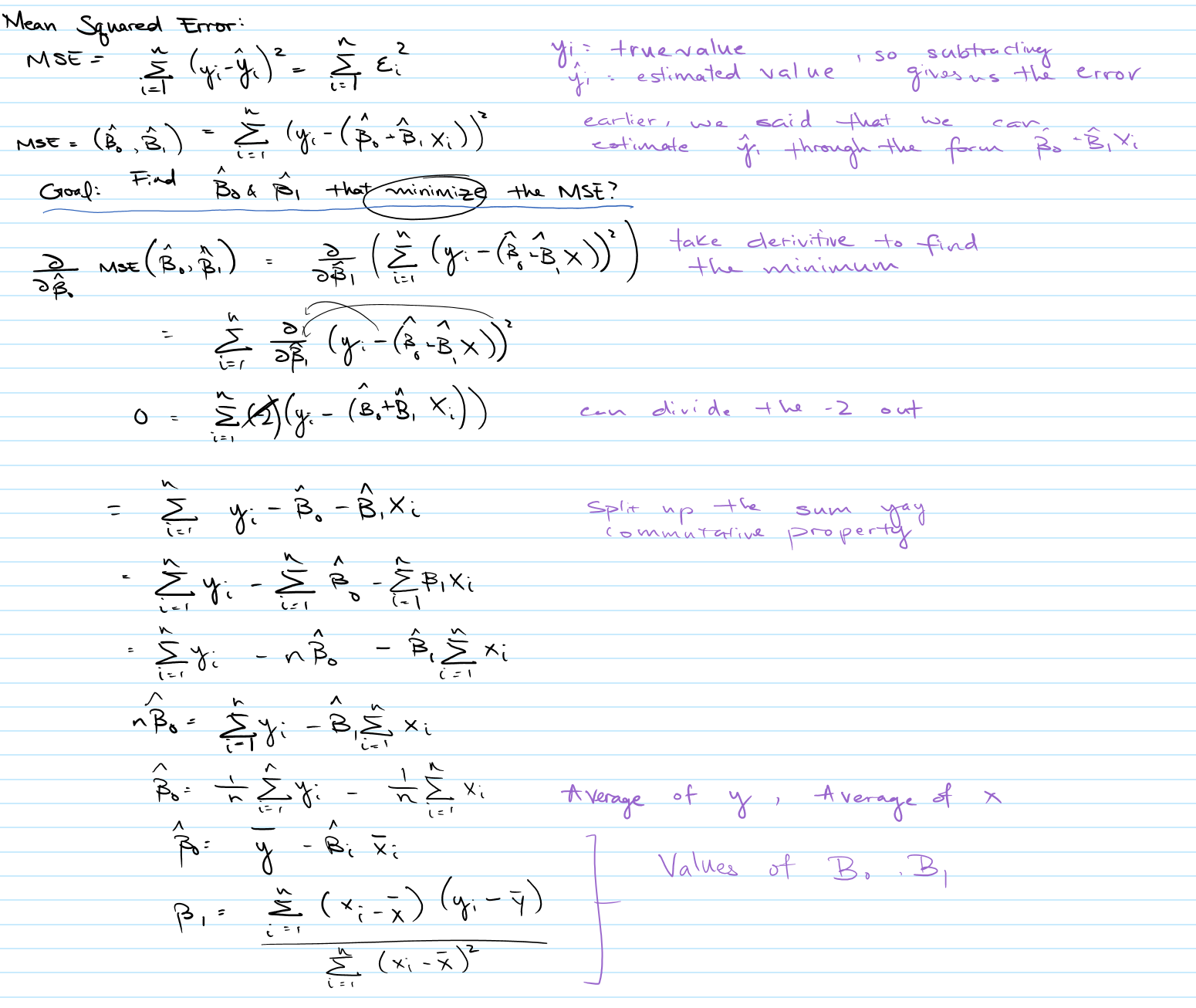
Similarly for \(B_0\).
Now that we have the values for \(B_0\) and \(B_1\), which minimize the error, we have everything we need for our model! But how good is this model? How do we know it’s not complete garbage?
Accuracy of Parameters
Again, we assume that we will always have some zero-mean error term in our model:
\[Y=\beta_0+\beta_1*X+\varepsilon\]Through the following, we can see that as we increase our dataset size, we will tend to converge towards our true model. We don’t know the actual true value of the \(\mu\), but we estimate it using \(\bar{Y}\). As we use more and more points in \(\bar{Y}\), we will see that our estimate for the mean of the will get closer to the true mean.
\[E[\bar{Y}]=E\bigg[\frac{1}{n}\sum_{i=1}^{n}Y_i\bigg]=\frac{1}{n}\sum_{i=1}^{n}E[Y_i]=\frac{1}{n}\sum_{i=1}^{n}\mu=\frac{n}{n\mu}=\mu\]Through this, we are able to calculate the standard error, and thus use this to calculate where our confidence interval is:
\[SE(\hat{\beta}_0)^2 = \sigma^2\bigg[\frac{1}{n} + \frac{\bar{x}^2}{\sum_{i=1}^{n}(x_i-\bar{x})^2}\bigg],\quad SE(\hat{\beta}_1)^2 = \frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}\]In other words, we are 95% confident that the true model is within the interval:
\[\hat{\beta}_1\pm2\cdot{SE}(\hat{\beta}_1)\] \[[\hat{\beta}_1-2\cdot{SE}(\hat{\beta}_1),\hat{\beta}_1+2\cdot{SE}(\hat{\beta}_1)]\]Similarly for \(B_0\).
Using the standard error, we can also use this to apply the null hypothesis, the idea that two groups are not related to each other, or the alternative hypothesis, that the two groups are somehow related to each other. Note that if \(B_1 = 0\), we can see that \(Y\) will not depend on feature \(X\):
\[\beta_1 = 0,\quad Y=\beta_0+\beta_1X+\varepsilon,\quad Y = \beta_0+\varepsilon\]In other words, we want to see a low probability that the null hypothesis is true. The smaller our p-value is, the less likely that our X and Y have no relationship to each other. (sorry for all the double negatives)
We can also use the similar t-statistic, calculated by:
\[t = \frac{\hat{\beta}_1 - 0}{SE(\hat{\beta}_1)}\]to calculate the number of standard deviations \(\hat{B}_1\) is away from 0. Mo’ big, Mo’ good.
These two describe how well our \(B_0\) and \(B_1\) is, but how well does the model actually fit to the data??
How good is our fit?
The first measure that we can look at to measure this is our residual standard error, which is related to the \(RSS\).
\[\text{RSE}=\sqrt{\frac{1}{n-2}\text{RSS}}=\sqrt{\frac{1}{n-2}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2}\]This tool tells us how far away we are from most of the data. It’s the average amount that the response will deviate from the true regression line. By itself it doesn’t mean much, but we can divide it by the mean value of our entire data set to receive our percent error. For example, the \(RSE\) of the Advertising dataset (from ISLR) is 3.26 (the actual sales from each market deviate from the true regression line by ~3260 units), and the mean is 14000, so the percent error of our model is ~3260/14000 = 23%.
We can also look at the R^2 Statistic. Consider the total sum of squares, the total variance in the outcome variable Y (how far away Y is from its mean, overall):
\[\text{TSS}=\sum_{i=1}^{n}(y_i-\bar{y})\]\(RSS\) measures the amount of variability that is left unexplained after performing the regression. Doing \(TSS - RSS\) gives you the amount of variability that is explained/removed by performing the regression. I.E: if \(TSS = RSS\), the variance in the data goes away with the regression–when \(Y\) is 100% linear.
\[\text{R}^2=\frac{\text{TSS-RSS}}{\text{RSS}}=1-\frac{\text{RSS}}{\text{TSS}}\]On the other hand, a \(R^2\) value near 0 means that the regression didn’t explain the variance that was in the response. This could be because our linear model was wrong, or that our initial error is high (or both).
In the case of simple linear regression, the \(R^2\) statistic is the same as the correlation between \(X\) and \(Y\).
Multi-Linear Regression, Polynomial regression
We can treat higher dimensions or higher order polynomials as their own columns. Ordinary least squares solves it all the same, but recall that we have to make assumptions about the form of our data, so it is super helpful and useful to visualize it before performing the linear regression. Additionally, we have several tools that we will discuss later about model selection and which models are better over others.
Implementation in Python here.