Classification
BACK: Linear Regression
UNDER HEAVY CONSTRUCTION: NOT EVERYTHING MAY BE CORRECT.
Let’s say instead of some quantitative value (linear regression), we wanted to predict a qualitative value. Based on somebody’s \(X_1, X_2, X_3\), what is the probability that they have disease \(A, B,\) or \(C\)?
Example the textbook gives: Based on a person’s income, account balance, and student status (if they are a student or not), will they default on a loan?

Previously, we looked at K Nearest Neighbors to determine if a new test point \(X\) would be in class A or class B, based on the training data points that are closest to \(X\). This was an example of classification, and we will continue to explore these ideas through logistic regression, linear discriminant analysis, and quadratic discriminant analysis.
Linear Regression?
Why can’t we just use linear regression to fit a line to the probability that point \(X\) is in class \(A\) or \(B\) or \(C\)?
Technically, it can work with binary classes, but there are much better methods to use instead. We would get some line that would describe the probability of being either class \(A\) or class \(B\), but we would have values of \(X\) where our \(Y\) (our probability of defaulting or not defaulting) would be outside the range [0,1], which poses problems in terms of probability (left picture below).
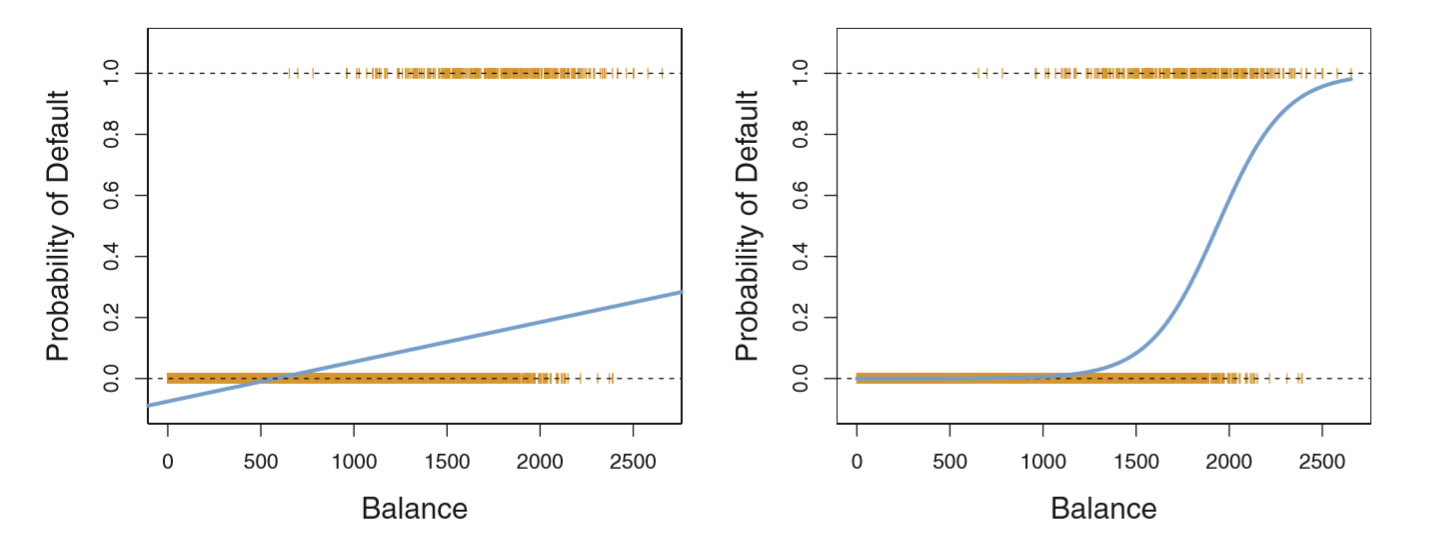
Instead, we want to fit a function where every value of \(X\) will be between [0,1]–there are many of these functions, but the most popular one is the logistic function (right picture).
Logistic Regression
Again, the goal of this model is to describe the probability that \(Y\) is class \(A\), given some parameter \(X\).
\[Pr(Y=A|X)\] \[Pr(default = Yes|balance)\]Abbreviating this to just \(p(X)\), we can set this equal to the logistic function.
\[p(X) = \frac{e^{\beta_0+\beta_1X}}{1 + e^{\beta_0+\beta_1X}}\]We use maximum likelihood estimation to calculate the values \(\beta_0\) and \(\beta_1\). It’s similar to the idea of linear regression, where we want to fit data to a linear model, but in this case, we are fitting our data to a normal distribution, and looking for those parameters needed to describe the distribution (for normal distribution, we are looking for \(\mu\) and \(\sigma^2\)).
Similarly for multiple logistic regression, we just add more parameters \(\beta_n\) to the exp().
These ideas also work for 2+ classes, but again, there are better tools for classifying several classes.
Linear Discriminant Analysis
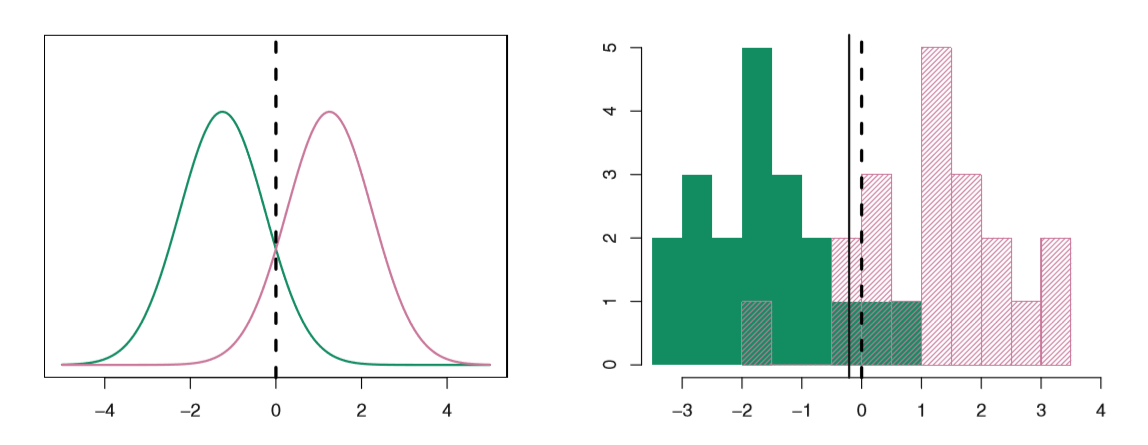
The goal of linear discriminant analysis is to draw some line that maximizes the separability of your classes AKA, maximize the means between the classes.
To do this, we create \(f_1(x), f_2(x), ... f_k(x)\), a probability density function for each class. In other words, \(f_k(x)=Pr(X=x|Y=k)\) . We want to be doing this for every class. What is the pdf for class 1, for class 2, for class k?
By putting all of these density functions onto one graph and then applying Baye’s Rule (literally my least favorite thing in the entire world), we find
\[Pr(Y=k|X=x) = \frac{\pi_kPr(X=x|Y=k)}{\sum_{i=1}^{K}\pi_iP(X=x)} = \frac{\pi_kf_k(x)}{\sum_{i=1}^{K}\pi_if_i(x)}\]- \(\pi_i\) is the prior knowledge–What is the probability that a sample is drawn from class i? What is the probability that a die roll is even?
- \(Pr(Y=k|X=x)\) is the posterior–What is the probability that this observation belongs to class i? What is the probability that the die I just rolled is a 2, knowing I rolled an even number?
Note: We said that \(Pr(X=x)\) is \({\sum_{i=1}^{K}\pi_if_i(x)}\). This essentially just says that we know that the class that we rolled is one of the known k categories.
Check out this Notebook for an example (Also, this explains Baye’s Theorem better than I’ve ever seen).
We end up with several probabilities for each category, and then pick the class with the highest. These ideas can be extended to multivariate LDA, as well as multi-class LDA. We end up using multivariate Gaussian distributions, but all of the ideas are the same.
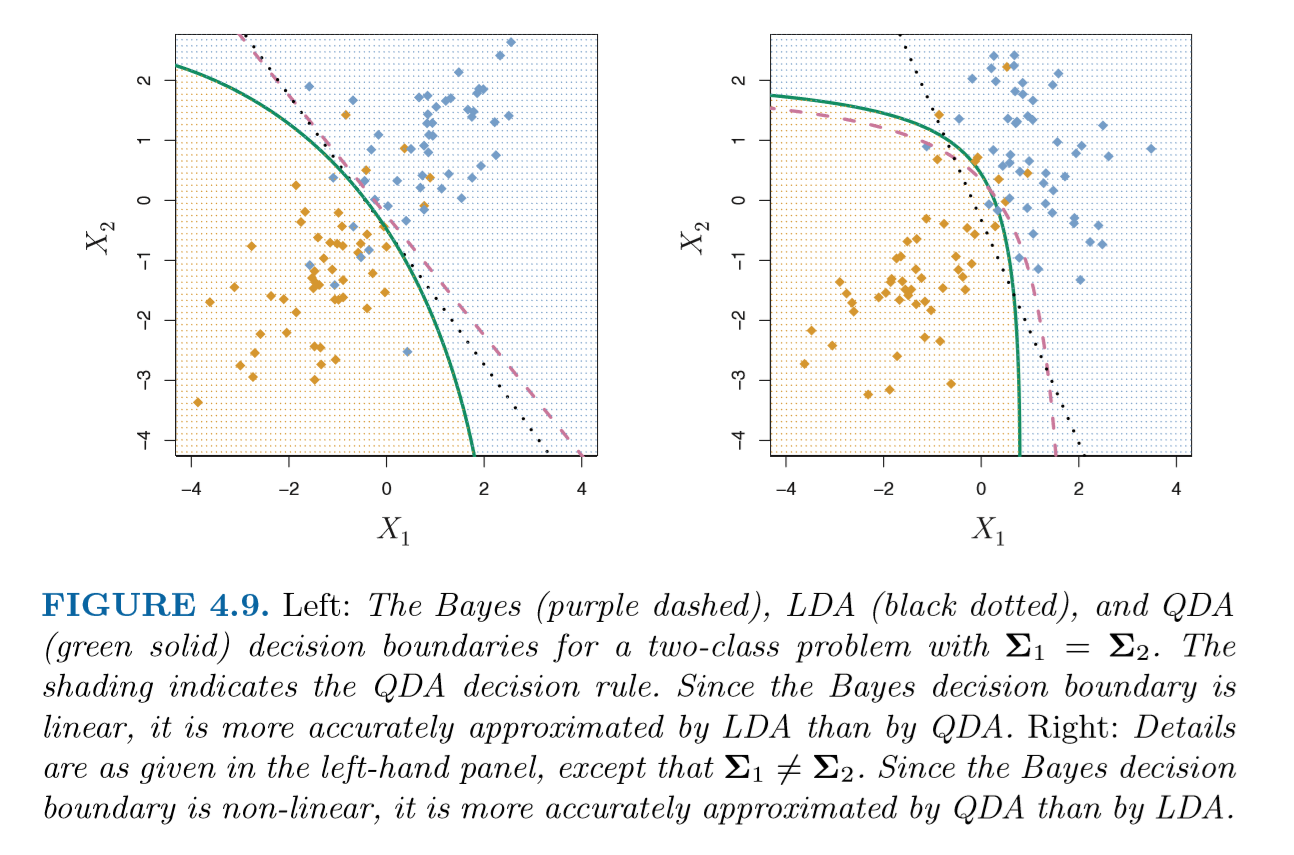
However, in LDA, we do not consider the different variances in our different distributions. We do this in quadratic discriminant analysis, though. Below, we can see the decision boundary line drawn by LDA. This is..linear because our discriminant function (?) is linear. This is not the case in Quadratic Discriminant Analysis.
Quadratic Discriminant Analysis
Confusion Matrices, ROC Curves
To further analyze our model, we can take a look at the confusion matrix associated with our dataset. This table uses a given input (usually a subset of the data) and then predicts every input, resulting in a small table that describes the number of correct and incorrect instances–as well as which label the incorrectly identified.