Graphs Basics
BACK: Greedy Programming
We’ve seen graphs in previous classes: a network of nodes or vertices that connect to each other through their edges. We try to turn every problem that we have into a graph: Maps for planning and perception, the Internet, social media, our friends, …
We can represent graphs in a bunch of different ways as well, but the book focuses on two different ways: a list of adjacency lists or an adjacency matrix.
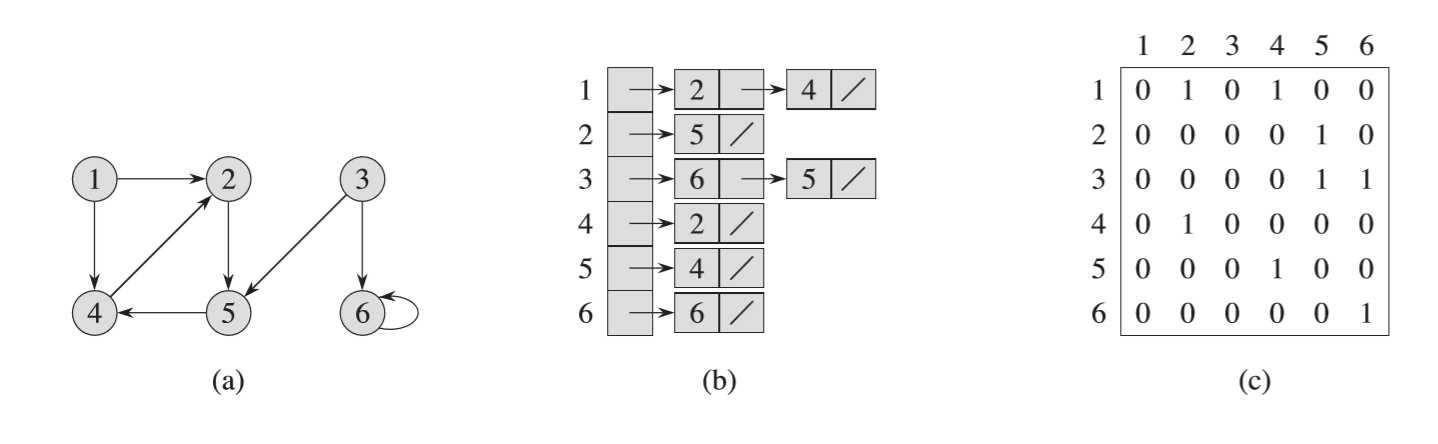
In directed graphs, the edges will have specific directions–the arrows will be one way. It will suggest that I can go from Vertex A to Vertex B but not the other way around.
Undirected graphs suggest the opposite–the lack of arrows tell us that we can travel bidirectionally. The transpose of a graph is when we invert all of the arrows, so now I can get from Vertex B to Vertex A but not the other way around.
These edges can also have weights that tell you what the cost is to travel on that path. For example, if Elk Grove is a Vertex and Sacramento is a second Vertex, the weight on an edge that connects them might be “10 minutes,” to describe how long it takes to travel between the two nodes.
In an directed acyclic graph, our graph doesn’t contain any cycles, i.e: For every vertex V, there is no path in the graph that leads back to itself. In the directed graph above, there is a cycle between vertices 2, 4, and 5; thus it is not a DAG. DAGs can be represented in a line, where the edges can only point in one direction.
Searching
Different situations and algorithms will require us to use different searching methods–particularly Breadth First Search and Depth First Search.
Breadth First Search (BFS)
BFS finds and generates a tree of every possible node that is reachable by its start node, \(s\). It begins by initializing a queue and placing the \(s\) into the queue. Until the queue is empty, it will continue to pop the queue and then add any children of the popped node into it–while also keeping track of which nodes have already been in the queue before (through its color).
The algorithm for BFS can be found on pg 595.
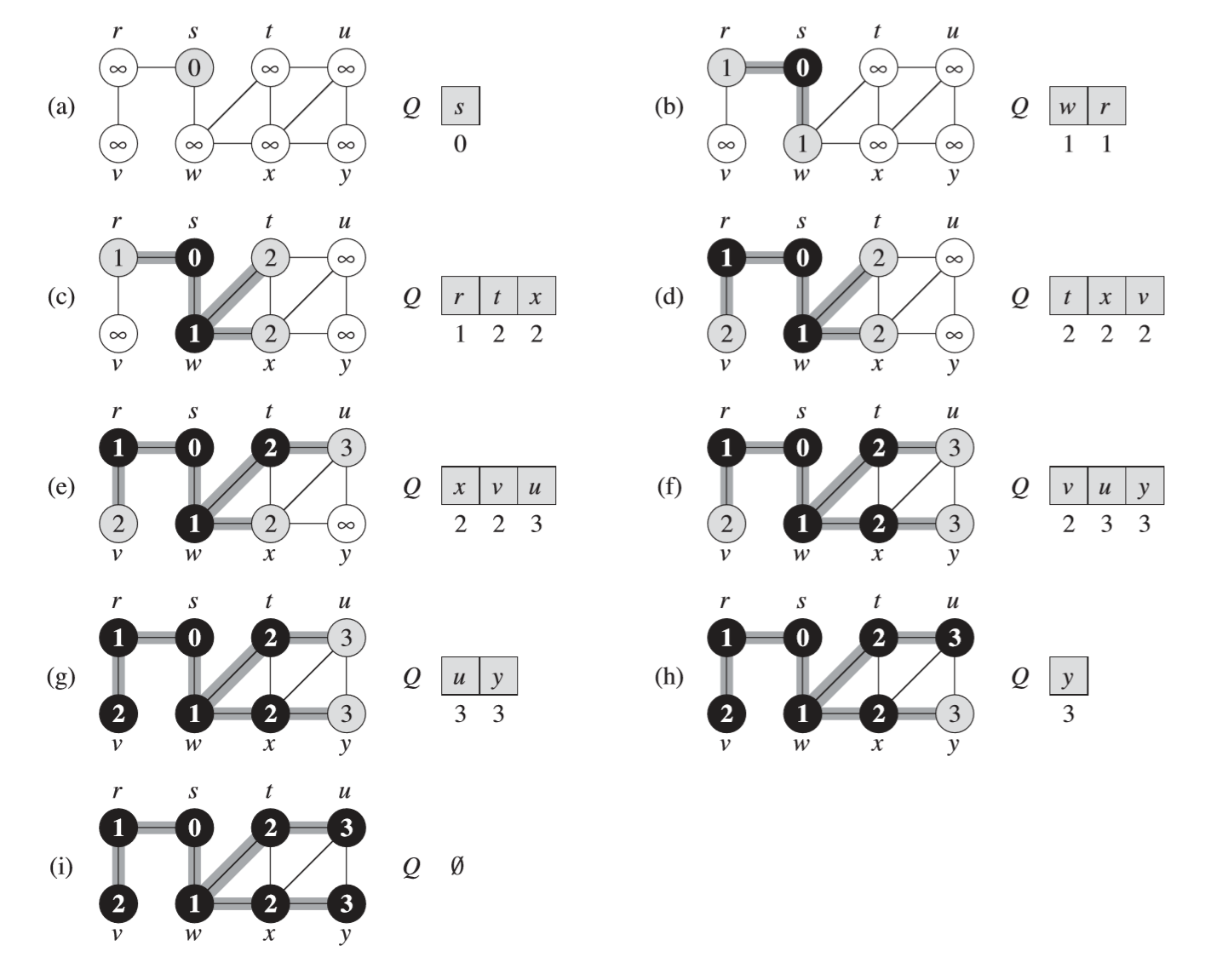
Through some analysis, we can see that the total running time of BFS is in \(O(V + E)\).
Further lemmas and whatnot about BFS can be found on pg 598, but essentially, BFS finds the shortest number of edges (shortest path) between \(s\) and any other vertex \(v\).
DFS
DFS, as it’s name suggests, searches with a priority of depth. We want to search through all of a children’s children’s children’s … children before we run back up the tree and search the first child’s sibling. Because of this, DFS uses a stack and doesn’t generate a single tree like BFS does–it generates a forest because it may have to randomly restart into a different node.
DFS also generates the starting sequence and the finishing sequence of each node–keeping track of when we order in which we visit each node and then when we exit it. It also does the same color scheme that BFS uses to keep track of a node’s state–if it’s been visited yet or not.
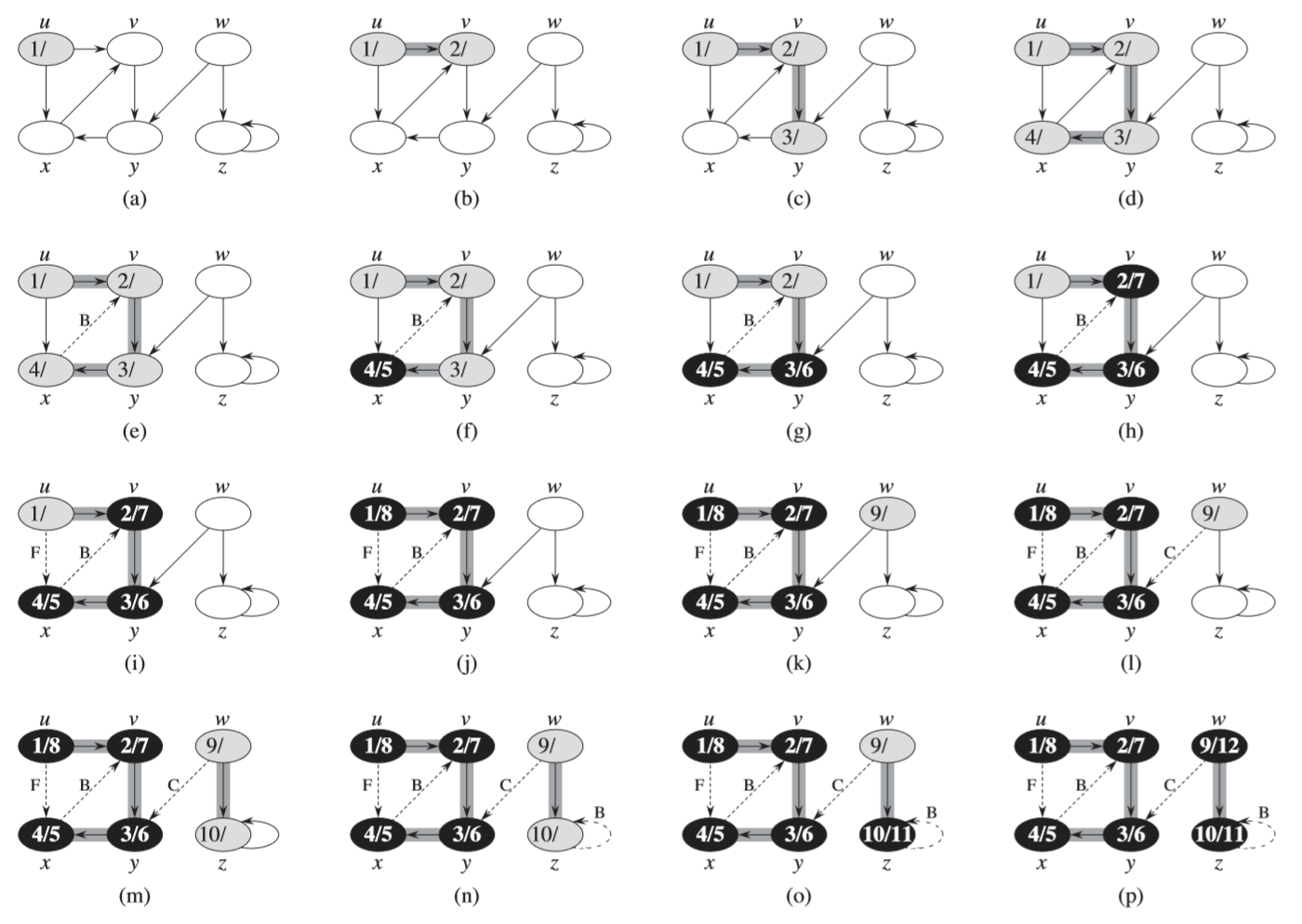
In this example (pg 605), we can also see that there the edges not included in the DFS forest (non tree edges), are labeled:
- Back Edge: The edge leads to a node that is gray (in the current subtree that we are exploring). The node leads back up the tree–to its parent’s or it’s parent’s parent (…).
- Forward Edge: The edge leads to a node that is black, but it one of the current node’s children. The node is leads forwards into the tree–to its child or it’s child’s child (…).
- Cross Edge: The DFS tree has restarted and taking this edge would lead into a different tree in the forest.
With more analysis, we can see that DFS runs in \(O(V + E)\) as well.
Topological Sort
Topological sorting tells us the possible order in which we can do something. The textbook example: putting on clothes. I can put my underwear on before my pants, but not the other way around.
By inputting a graph of every possible valid move you can do, following the topological sort pseudocode on pg 613 outputs a DAG which sorts valid moves from left to right.

The solution for the given input (top) is not unique. Depending on our starting vertex and which vertices we randomly restart into, we could have different DAG outputs, but the order should still make sense–I still shouldn’t put my shoes on before my socks.
Strongly Connected Components
This is a fun one. In a strongly connected component, every vertex inside the SCC can be reached from all of the other vertices. The cycles can be found by following pseudocode on page 617.
We start by performing DFS on the graph, while storing the nodes in order of their finishing time into a stack. When finished, we can then perform DFS on the transpose of the graph in order of the stack. The vertices that we find here will be the strongly connected components in the original graph.
These are some of the things we can do with graphs, but we will explore more about them and begin implementing weights to edges in the next section.